Statistiques descriptives avec DBMS_STAT_FUNCS
Lors de l’analyse de données, il est commun d’afficher les principales statistiques d’un échantillon. C’est ce que permet de faire la procédure SUMMARY du package DBMS_STAT_FUNCS.
Celle-ci balaye toutes les données d’un champ numérique passé en argument pour restituer les principales caractéristiques descriptives (min/max, variance, quantiles…).
La procédure renvoie un objet de type DBMS_STAT_FUNCS.summarytype et il est donc nécessaire de coder un wrapper en PL/SQL pour afficher les informations. C’est ce que fait la fonction STAT_SUMMARY que voici: stat_summary_func.
Elle renvoie un rapport sous la forme d’un CLOB qu’il est alors possible d’afficher sous SQL*Plus:
SQL> DESC duree_vie
Name Null? Type
----------------------------------------- -------- ----------------------------
PAYS VARCHAR2(70)
ESP NUMBER
SQL> SET HEAD OFF
SQL> SET PAGES 100
SQL> SET LONG 10000 LONGC 10000
SQL>
SQL> SELECT stat_summary ('duree_vie', 'esp') FROM DUAL;
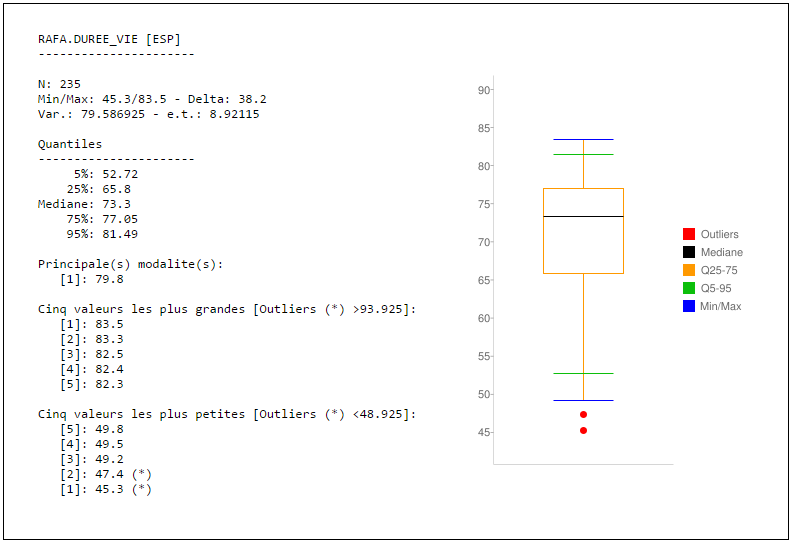
RAFA.DUREE_VIE [ESP]
----------------------
N: 235
Min/Max: 45.3/83.5 - Delta: 38.2
Var.: 79.586925 - e.t.: 8.92115
Quantiles
----------------------
5%: 52.72
25%: 65.8
Mediane: 73.3
75%: 77.05
95%: 81.49
Principale(s) modalite(s):
[1]: 79.8
Cinq valeurs les plus grandes [Outliers (*) >93.925]:
[1]: 83.5
[2]: 83.3
[3]: 82.5
[4]: 82.4
[5]: 82.3
Cinq valeurs les plus petites [Outliers (*) <48.925]:
[1]: 45.3 (*)
[2]: 47.4 (*)
[3]: 49.2
[4]: 49.5
[5]: 49.8
SQL>
Le problème de DBMS_STAT_FUNCS.summary est que la procédure analyse la totalité des données du champ ciblé. Or, bien souvent, c’est uniquement sur un sous-ensemble des données que l’on souhaite travailler.
Dans ce cas, je passe par la création d’une vue qui opère (de manière plus ou moins complexe) le filtrage souhaité. Dans l’exemple ci-dessous je m’intéresse uniquement aux données d’espérance de vie relatives aux pays de l’UE (ces derniers sont listés dans la table EUROPE). Je créée donc une vue DUREE_VIE_EUROPE qui réalise la jointure sur ces deux tables:
SQL> CREATE OR REPLACE VIEW duree_vie_europe 2 AS 3 SELECT pays, esp 4 FROM duree_vie JOIN europe USING (pays); View created. SQL>
Je peux alors invoquer DBMS_STAT_FUNCS.summary sur cette vue (au même titre que si c’était une table) via ma fonction STAT_SUMMARY:
SQL> SELECT stat_summary ('duree_vie_europe', 'esp') FROM DUAL;
RAFA.DUREE_VIE_EUROPE [ESP]
----------------------
N: 28
Min/Max: 72.1/82.3 - Delta: 10.2
Var.: 10.247765 - e.t.: 3.201213
Quantiles
----------------------
5%: 72.59
25%: 76.05
Mediane: 79.8
75%: 80.7
95%: 81.895
Principale(s) modalite(s):
[1]: 72.1
[2]: 79.8
[3]: 81.7
[4]: 80.7
[5]: 80.4
[6]: 80.5
Cinq valeurs les plus grandes [Outliers (*) >87.675]:
[1]: 82.3
[2]: 82
[3]: 81.7
[4]: 81.7
[5]: 81
Cinq valeurs les plus petites [Outliers (*) <69.075]:
[1]: 72.1
[2]: 72.1
[3]: 73.5
[4]: 73.7
[5]: 74.3
SQL>
Cela-dit, j’utilise assez peu souvent cette approche directe en SQL. En pratique, j’invoque la fonction STAT_SUMMARY depuis SQL*Plus via un script « stat_summary.sql » qui permet de générer directement la sortie au format HTML et de l’ouvrir dans mon navigateur.
Le script est disponible ici: stat_summary. A noter qu’il faut changer son extension en « .sql » après le téléchargement.
Cerise sur le gâteau: un boxplot est affiché via Google Chart Image ce qui facilite grandement la compréhension visuelle des informations!
SQL> @stat_summary.sql duree_vie esp SQL>