ANOVA à un facteur avec R
Dans la continuité du précédent billet, en utilisant le même jeu de données, je réalise cette fois-ci le test ANOVA avec R.
Chargement et préparation des données
Les données sont chargées dans un dataframe « petrol » dont on ne conserve que les champs d’intérêt pour la suite de l’analyse. Les prix sont convertis au format numérique (ils sont sous forme de facteur initialement) et on supprime les lignes anciennes (plus d’une semaine):
> petrol <- read.csv2("C:/RTI/Stats/prix_des_carburants_j_7.csv", encoding="UTF-8")
> petrol <- petrol[,c(3,14,15,22)]
> names(petrol) <- c("Axe","MAJ","Gazole","Marque")
>
> petrol$Gazole <- as.numeric(levels(petrol$Gazole))[petrol$Gazole]
>
> petrol <- petrol[which(!is.na(petrol$Gazole)),]
>
> petrol$MAJ <- as.Date(substr(petrol$MAJ,1,10))
> petrol <- petrol[which(petrol$MAJ>=as.Date("2015-06-03")),]
>
Groupement des données
On adjoint un champ type_distrib qui va servir à grouper les lignes par canal de distribution: « Grande Distribution », « Distributeur » et « Distrib. Low Cost ». Tout comme lors de la réalisation du test par Oracle, on utilise les marques des stations comme critère de classification. On exclut cette fois encore les stations d’autoroute et les stations indépendantes:
> petrol$type_distrib <- "?"
>
> petrol$type_distrib[which(petrol$Marque %in% c("Agip","Esso","BP","Avia","Total","Elan","Shell","Dyneff","VITO"))] <- "Distributeur"
>
> petrol$type_distrib[which(petrol$Marque %in% c("Intermarché","Système U","Auchan","Leclerc", "Carrefour", "Carrefour Market", "Carrefour Contact", "Atac", "Casino", "Colruyt","CORA","Géant","Netto", "Leader Price","Ecomarché","Intermarché Contact","Super Casino","Supermarché Match","Simply Market","Shopi"))] <- "Grande Distribution"
>
> petrol$type_distrib[which(petrol$Marque %in% c("Esso Express", "Total Access"))] <- "Distrib. Low Cost"
>
> petrol$type_distrib[which(petrol$Axe=="A")] <- "?"
> petrol <- petrol[which(petrol$type_distrib!="?"),]
>
> table(petrol$type_distrib[])
Distrib. Low Cost Distributeur Grande Distribution
358 1203 3834
>
Les effectifs sont identiques à ceux précédemment obtenus avec Oracle.
Vérification de l’homoscédasticité
> aggregate(Gazole~type_distrib, data=petrol, var)
type_distrib Gazole
1 Distrib. Low Cost 0.0002230324
2 Distributeur 0.0010942950
3 Grande Distribution 0.0007174682
>
On retrouve les même variances que lors de l’analyse menée avec Oracle. L’amplitude de la différence de ces dernières appelle à la vigilance (cf post précédent).
Réalisation du test ANOVA
> anova_res <- aov(Gazole~type_distrib, data=petrol)
> summary(anova_res)
Df Sum Sq Mean Sq F value Pr(>F)
type_distrib 2 7.940 3.970 5164 <2e-16 ***
Residuals 5392 4.145 0.001
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
>
La p-value est très faible et on rejette l’hypothèse nulle. Il y a donc au moins un groupe dont la moyenne de prix est statistiquement différente des autres.
Contrairement à l’analyse réalisée avec Oracle, on dispose cette fois-ci de tests post-hoc permettant de déterminer l’origine de la différence.
Réalisation du test post-hoc
On utilise ici un test HSD de Tuckey dont l’hypothèse nulle est qu’il n’y a pas de différence significative entre les moyennes des groupes.
> tukey_res <- TukeyHSD(anova_res)
> tukey_res
Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = Gazole ~ type_distrib, data = petrol)
$type_distrib
diff lwr upr p adj
Distributeur-Distrib. Low Cost 0.08912650 0.085213249 0.093039754 0.0000000
Grande Distribution-Distrib. Low Cost -0.00329578 -0.006887925 0.000296364 0.0799709
Grande Distribution-Distributeur -0.09242228 -0.094570300 -0.090274265 0.0000000
>
L’hypothèse H0 est rejetée pour deux combinaisons – à savoir, « Distributeur »/ »Distrib. Low Cost » et « Distributeur »/ »Grande Distribution ». On peut donc dire qu’il existe une différence statistiquement significative entre les moyennes de prix entre le groupe « Distributeur » et les groupes « Distrib. Low Cost » et « Grande Distribution ».
En revanche, la p-value dépasse le seuil de 5% pour la combinaison « Grande Distribution »/ »Distrib. Low Cost ». On ne peut donc pas affirmer qu’il existe une différence de moyenne significative entre ces deux groupes.
Analyse graphique
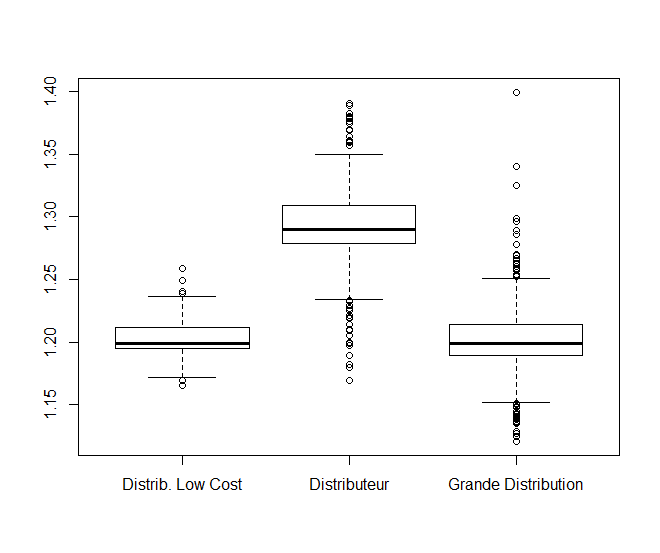
La représentation de la distribution des prix par groupe via un boxplot (dont on exclut les valeurs extrêmes – à savoir, 11 valeurs hors de la fenêtre 1.1€ – 1.4€) permet de corroborer visuellement le résultat du test HSD de Tukey.
> boxplot(Gazole~type_distrib, data=petrol[which(petrol$Gazole>1.1 & petrol$Gazole<1.4),])
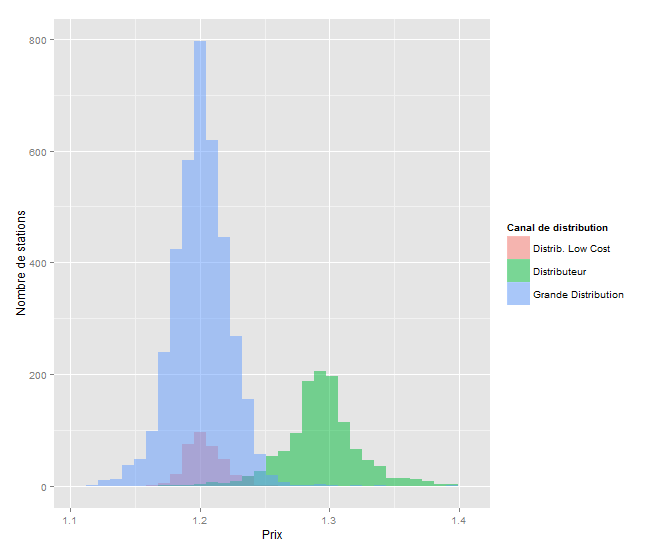
On peut aussi représenter au sein d’un même graphique les histogrammes des 3 groupes. Le recouvrement est clair entre les groupes « Distributeur Low Cost » et « Grande Distribution » alors que l’histogramme du groupe « Distributeur » est clairement décalé vers la droite.
> library(ggplot2)
> ggplot(petrol[which(petrol$Gazole>1.1 & petrol$Gazole<1.4),], aes(Gazole, fill = type_distrib)) + geom_histogram(alpha = 0.5, position = 'identity') + xlab("Prix") + ylab("Nombre de stations") + scale_fill_discrete(name="Canal de distribution")
stat_bin: binwidth defaulted to range/30. Use 'binwidth = x' to adjust this.
>