Régression linéaire multiple avec R
Dans la continuité du précédent billet, je réalise cette fois-ci la régression multiple avec R. Le jeu de données utilisé est identique.
Récupération des données depuis le SGBD
> library(ROracle) > ora = Oracle() > cnx = dbConnect(ora, username="rafa", password="rafa", dbname="S1401037:1521/STATPDB") > ImmoParis <- dbGetQuery(cnx, "select * from immo_paris_v") > dbDisconnect(cnx) [1] TRUE >
Normalisation des informations
Les variables catégorielles sont transformées en facteurs:
> ImmoParis$ARRONDISSEMENT <- factor(ImmoParis$ARRONDISSEMENT)
> ImmoParis$BALCON <- factor(ImmoParis$BALCON)
> ImmoParis$CAVE <- factor(ImmoParis$CAVE)
> ImmoParis$PARKING <- factor(ImmoParis$PARKING)
> ImmoParis$GARDIEN <- factor(ImmoParis$GARDIEN)
> summary(ImmoParis)
PRIX NBPIECES NBCHAMBRES PARKING BALCON CAVE GARDIEN SUPERFICIE ARRONDISSEMENT
Min. : 46000 Min. :1.000 Min. :0.000 0:300 0:274 0:162 0:275 Min. : 4.80 75018 : 50
1st Qu.:209750 1st Qu.:1.000 1st Qu.:1.000 1: 32 1: 58 1:170 1: 57 1st Qu.:25.00 75020 : 40
Median :294500 Median :2.000 Median :1.000 Median :35.48 75014 : 35
Mean :298556 Mean :1.913 Mean :1.006 Mean :36.91 75019 : 34
3rd Qu.:394625 3rd Qu.:2.000 3rd Qu.:1.000 3rd Qu.:47.95 75011 : 31
Max. :499000 Max. :5.000 Max. :5.000 Max. :77.00 75013 : 27
(Other):115
>
Etude de la colinéarité
Le VIF des variables peut être obtenu par la fonction vif de la librairie CAR. On retrouve bien les mêmes chiffres que lors de l’étude réalisée à partir d’Oracle. On exclut donc cette fois encore la variable NBPIECES:
> res <- lm(PRIX~., data=ImmoParis)
> library(car)
> ### Analyse de colinéarité
> vif(res)
GVIF Df GVIF^(1/(2*Df))
NBPIECES 6.539100 1 2.557166
NBCHAMBRES 3.912744 1 1.978066
PARKING 1.231601 1 1.109775
BALCON 1.238437 1 1.112851
CAVE 1.304018 1 1.141936
GARDIEN 1.189156 1 1.090484
SUPERFICIE 4.502493 1 2.121908
ARRONDISSEMENT 2.428668 18 1.024955
>
> res <- lm(PRIX~. -NBPIECES, data=ImmoParis)
> vif(res)
GVIF Df GVIF^(1/(2*Df))
NBCHAMBRES 2.504415 1 1.582534
PARKING 1.215899 1 1.102678
BALCON 1.231309 1 1.109643
CAVE 1.303490 1 1.141705
GARDIEN 1.182347 1 1.087358
SUPERFICIE 2.505841 1 1.582985
ARRONDISSEMENT 2.168864 18 1.021739
>
Détermination des prédicteurs par la méthode stepwise
A l’instar de la fonctionnalité de « feature selection » d’ODM, on peut utiliser la fonction step pour réaliser une détermination pas à pas (basée sur l’AIC) de la meilleure combinaison de prédicteurs.
> stepw <- step(res, direction="both")
Start: AIC=6942.85
PRIX ~ (NBPIECES + NBCHAMBRES + PARKING + BALCON + CAVE + GARDIEN +
SUPERFICIE + ARRONDISSEMENT) - NBPIECES
Df Sum of Sq RSS AIC
- GARDIEN 1 5.8483e+07 3.4503e+11 6940.9
- BALCON 1 6.7118e+07 3.4504e+11 6940.9
- NBCHAMBRES 1 1.2915e+09 3.4627e+11 6942.1
- PARKING 1 1.4300e+09 3.4641e+11 6942.2
<none> 3.4498e+11 6942.9
- CAVE 1 7.3252e+09 3.5230e+11 6947.8
- ARRONDISSEMENT 18 3.0846e+11 6.5343e+11 7118.9
- SUPERFICIE 1 1.6239e+12 1.9689e+12 7519.1
Step: AIC=6940.91
PRIX ~ NBCHAMBRES + PARKING + BALCON + CAVE + SUPERFICIE + ARRONDISSEMENT
Df Sum of Sq RSS AIC
- BALCON 1 6.0791e+07 3.4510e+11 6939.0
- PARKING 1 1.4011e+09 3.4644e+11 6940.3
- NBCHAMBRES 1 1.4506e+09 3.4648e+11 6940.3
<none> 3.4503e+11 6940.9
+ GARDIEN 1 5.8483e+07 3.4498e+11 6942.9
- CAVE 1 7.5937e+09 3.5263e+11 6946.1
- ARRONDISSEMENT 18 3.1054e+11 6.5557e+11 7118.0
- SUPERFICIE 1 1.6832e+12 2.0282e+12 7527.0
Step: AIC=6938.97
PRIX ~ NBCHAMBRES + PARKING + CAVE + SUPERFICIE + ARRONDISSEMENT
Df Sum of Sq RSS AIC
- NBCHAMBRES 1 1.4338e+09 3.4653e+11 6938.3
- PARKING 1 1.6356e+09 3.4673e+11 6938.5
<none> 3.4510e+11 6939.0
+ BALCON 1 6.0791e+07 3.4503e+11 6940.9
+ GARDIEN 1 5.2156e+07 3.4504e+11 6940.9
- CAVE 1 7.5740e+09 3.5267e+11 6944.2
- ARRONDISSEMENT 18 3.1534e+11 6.6044e+11 7118.5
- SUPERFICIE 1 1.6925e+12 2.0376e+12 7526.5
Step: AIC=6938.34
PRIX ~ PARKING + CAVE + SUPERFICIE + ARRONDISSEMENT
Df Sum of Sq RSS AIC
- PARKING 1 1.4649e+09 3.4799e+11 6937.7
<none> 3.4653e+11 6938.3
+ NBCHAMBRES 1 1.4338e+09 3.4510e+11 6939.0
+ GARDIEN 1 2.0568e+08 3.4632e+11 6940.1
+ BALCON 1 4.3968e+07 3.4648e+11 6940.3
- CAVE 1 7.5455e+09 3.5407e+11 6943.5
- ARRONDISSEMENT 18 3.2207e+11 6.6859e+11 7120.5
- SUPERFICIE 1 2.9126e+12 3.2591e+12 7680.4
Step: AIC=6937.74
PRIX ~ CAVE + SUPERFICIE + ARRONDISSEMENT
Df Sum of Sq RSS AIC
<none> 3.4799e+11 6937.7
+ PARKING 1 1.4649e+09 3.4653e+11 6938.3
+ NBCHAMBRES 1 1.2631e+09 3.4673e+11 6938.5
+ BALCON 1 2.4356e+08 3.4775e+11 6939.5
+ GARDIEN 1 1.2345e+08 3.4787e+11 6939.6
- CAVE 1 7.2543e+09 3.5525e+11 6942.6
- ARRONDISSEMENT 18 3.2847e+11 6.7646e+11 7122.4
- SUPERFICIE 1 3.0115e+12 3.3595e+12 7688.5
>
La succession d’itération conduit à finalement à conserver le n-uplet CAVE, SUPERFICIE et ARRONDISSEMENT. Il est intéressant de noter que ce ne sont pas les mêmes prédicteurs que ceux auxquels la fonctionnalité de « feature selection » d’ODM est parvenue.
Analyse du modèle
Même si les prédicteurs auxquels aboutissent les deux approches sont différents, le R2 reste très proche et élevé (de l’ordre de 91%):
> res <- lm(PRIX ~ CAVE + SUPERFICIE + ARRONDISSEMENT, data=ImmoParis)
> summary(res)
Call:
lm(formula = PRIX ~ CAVE + SUPERFICIE + ARRONDISSEMENT, data = ImmoParis)
Residuals:
Min 1Q Median 3Q Max
-92193 -20335 -798 18608 105249
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 118225.5 33619.2 3.517 0.000502 ***
CAVE1 10586.1 4157.6 2.546 0.011372 *
SUPERFICIE 6706.7 129.3 51.878 < 2e-16 ***
ARRONDISSEMENT75002 -44128.0 36135.2 -1.221 0.222938
ARRONDISSEMENT75004 1787.2 38661.5 0.046 0.963158
ARRONDISSEMENT75005 38996.6 40969.1 0.952 0.341910
ARRONDISSEMENT75006 -57852.7 41011.5 -1.411 0.159348
ARRONDISSEMENT75007 29061.0 35778.5 0.812 0.417271
ARRONDISSEMENT75008 -4547.0 47315.1 -0.096 0.923503
ARRONDISSEMENT75009 -50682.7 37425.9 -1.354 0.176651
ARRONDISSEMENT75010 -64342.7 34137.5 -1.885 0.060387 .
ARRONDISSEMENT75011 -52656.4 34035.0 -1.547 0.122850
ARRONDISSEMENT75012 -66473.5 34441.3 -1.930 0.054510 .
ARRONDISSEMENT75013 -55508.2 34155.5 -1.625 0.105142
ARRONDISSEMENT75014 -49996.2 34010.4 -1.470 0.142565
ARRONDISSEMENT75015 -58493.1 34198.9 -1.710 0.088193 .
ARRONDISSEMENT75016 -60975.7 36163.2 -1.686 0.092775 .
ARRONDISSEMENT75017 -56077.3 34734.0 -1.614 0.107437
ARRONDISSEMENT75018 -114471.5 33834.7 -3.383 0.000808 ***
ARRONDISSEMENT75019 -106194.4 34078.0 -3.116 0.002003 **
ARRONDISSEMENT75020 -103040.5 34021.1 -3.029 0.002662 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 33450 on 311 degrees of freedom
Multiple R-squared: 0.9183, Adjusted R-squared: 0.9131
F-statistic: 174.8 on 20 and 311 DF, p-value: < 2.2e-16
>
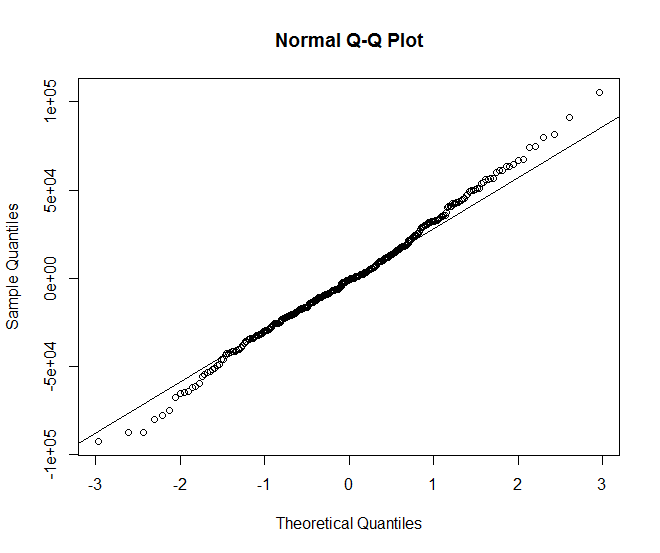
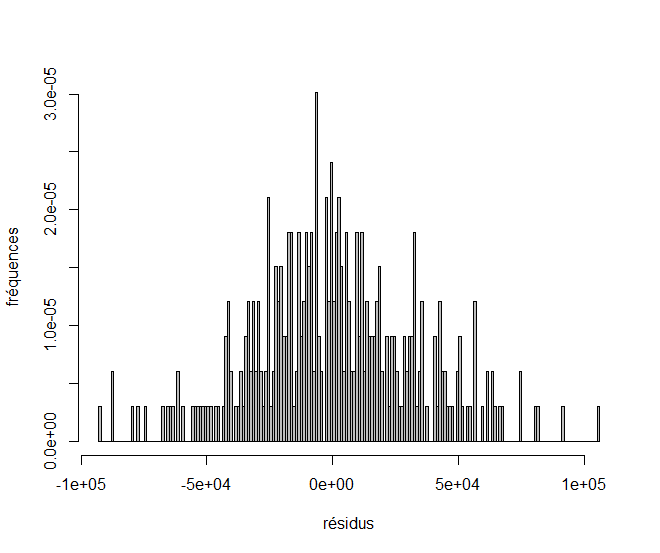
Vérification de la normalité des résidus
On peut valider la normalité des résidus par diverses méthodes: visualisation de la droite de Henry, analyse de l’aspect de l’histogramme ou bien plus rigoureusement avec un test de Shapiro:
> qqnorm(resid(res));qqline(resid(res));
> hist(resid(res), freq = F, col ="grey", main="", xlab="résidus", ylab="fréquences", nclass=200)
> shapiro.test(resid(res)) Shapiro-Wilk normality test data: resid(res) W = 0.9951, p-value = 0.3684 >
La p-valeur est supérieure au seuil et on ne peut donc pas rejeter l’hypothèse H0. Les données sont donc compatibles avec une distribution normale.
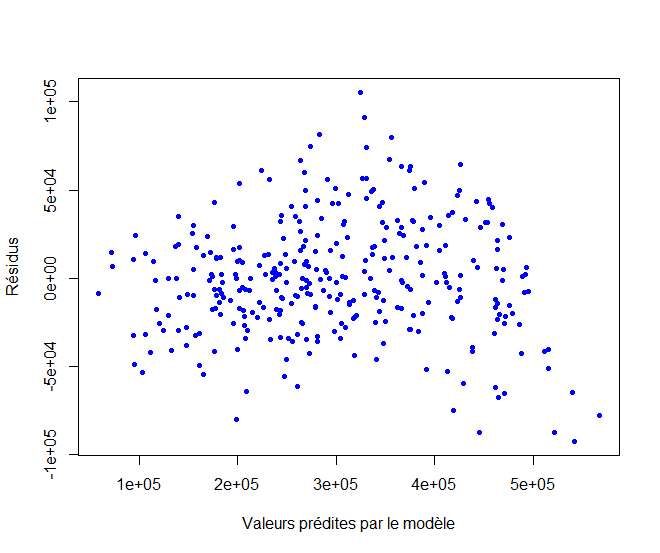
De même on peut vérifier l’homoscédasticité des résidus en vérifiant visuellement que le nuage de point est bien épars de manière symétrique autour de 0:
> plot(res$fitted.values, res$residuals, + xlab="Valeurs prédites par le modèle", + ylab="Résidus", pch=16, cex=0.75, col="blue") >
On peut aussi recourir à un test de Breush-Pagan pour cette validation:
> library(lmtest) > bptest(res) studentized Breusch-Pagan test data: res BP = 28.3765, df = 20, p-value = 0.1008 >
Ici, l’hypothèse H0 d’homoscédasticité ne peut pas être rejetée au seuil de 5%.
Simulation
La fonction PREDICT permet de simuler le prix d’un appartement en utilisant le modèle précédemment créé. On peut par exemple estimer le prix d’un deux pièces de 23m2 dans le 20eme arrondissement avec une cave:
> predict(res,data.frame(SUPERFICIE=23,CAVE="1",ARRONDISSEMENT="75020"))
1
180025.4
>