Partitionnement via k-means avec R
Dans la continuité du précédent billet, j’essaye ici de réaliser un partitionnement via k-means à l’aide de R. Les mêmes données de votes sont utilisées et elles sont accédées directement en base à l’aide de RODBC.
En pratique, on récupère les données de la vue V_VOTES_PART (contenant le codage des votes sous forme de variables indicatrices) au sein du dataframe votes2part:
> library(ROracle) Le chargement a nécessité le package : DBI Warning message: le package ‘DBI’ a été compilé avec la version R 3.2.1 > ora = Oracle() > cnx = dbConnect(ora, username="rafa", password="rafa", dbname="S1401037:1521/STATPDB") > votes2part <- dbGetQuery(cnx, "select * from v_votes_part") > dbDisconnect(cnx) [1] TRUE >
Le dataframe votes2part contient 497 lignes et 194 colonnes:
> dim(votes2part) [1] 497 194 >
Le partitionnement est effectué à l’aide de la commande kmeans à laquelle on passe le dataframe votes2part à l’exception des champs DEPUTE et PARTI (colonnes 1 et 2) ainsi que le nombre de partitions souhaitées: 6.
> clu <- kmeans(votes2part[,3:dim(votes2part)[2]],6) >
On construit ensuite un nouveau dataframe (res) regroupant pour chaque ligne de votes2part le parti d’origine du député ainsi que la partition auquel le k-means l’a affecté.
Cela permet de produire une table de contingence afin de visualiser la performance du partitionnement:
> res <- data.frame(clu$cluster,votes2part$PARTI)
> distrib <- table(res$votes2part.PARTI,res$clu.cluster)
> distrib
1 2 3 4 5 6
Groupe de l'union des démocrates et indépendants 0 0 22 0 0 0
Groupe de la gauche démocrate et républicaine 7 0 1 0 0 0
Groupe écologiste 16 0 0 0 0 0
Groupe Les Républicains 0 0 0 0 184 0
Groupe radical, républicain, démocrate et progressiste 0 11 0 1 0 1
Groupe socialiste, républicain et citoyen 0 3 0 216 0 35
>
A l’aide d’un barplot, on peut aussi représenter graphiquement la distribution de l’origine des députés au sein de chaque partition:
> colpartis <- c("mediumpurple", "red", "green3", "lightskyblue", "lemonchiffon", "lightpink")
> barplot(distrib, main="Distribution des députés par partition",xlab="Partition", col=colpartis, legend=rownames(distrib), args.legend = list(x = "topleft", bty = "n", inset=c(0, 0)))
>
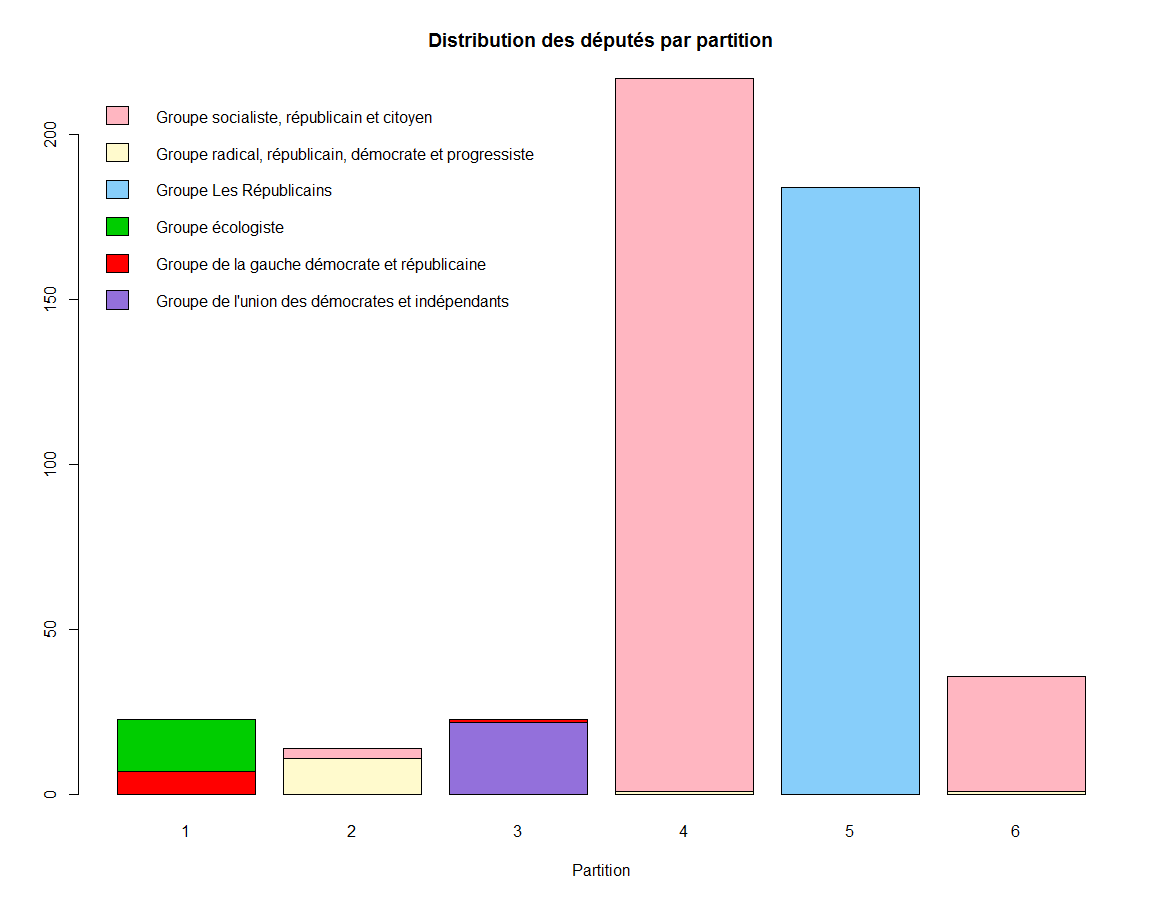
On voit que le partitionnement est relativement efficace.
En revanche, si on réitère l’opération, on constate un résultat différent:
> clu <- kmeans(votes2part[,3:dim(votes2part)[2]],6)
> res <- data.frame(clu$cluster,votes2part$PARTI)
> distrib <- table(res$votes2part.PARTI,res$clu.cluster)
> distrib
1 2 3 4 5 6
Groupe de l'union des démocrates et indépendants 0 0 0 0 0 22
Groupe de la gauche démocrate et républicaine 8 0 0 0 0 0
Groupe écologiste 0 0 0 0 16 0
Groupe Les Républicains 0 32 101 51 0 0
Groupe radical, républicain, démocrate et progressiste 0 0 0 0 13 0
Groupe socialiste, républicain et citoyen 0 0 0 0 254 0
>
> barplot(distrib, main="Distribution des députés par partition",xlab="Partition", col=colpartis, legend=rownames(distrib), args.legend = list(x = "topleft", bty = "n", inset=c(0, 0)))
>
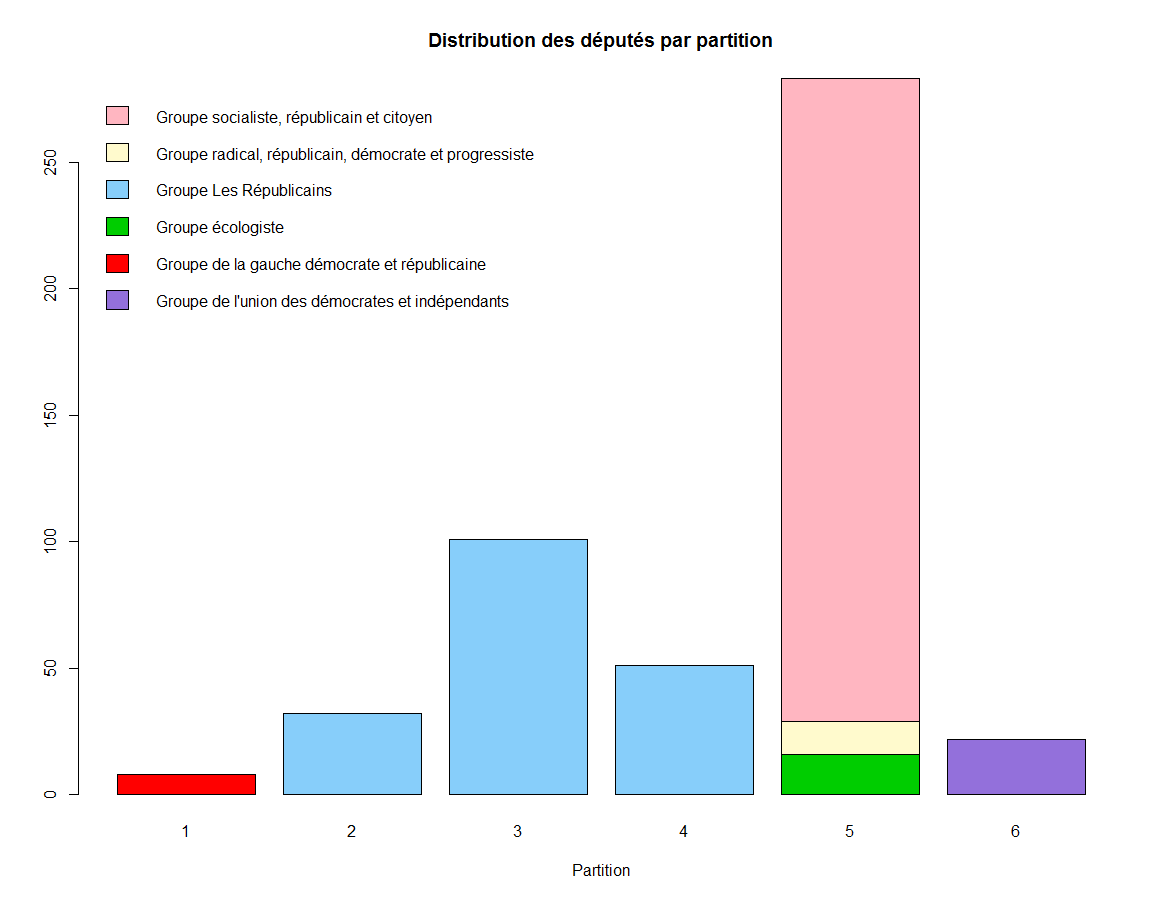
En fait, la performance du k-means est très dépendante du choix des points initiaux. Sans précision particulière, ceux-ci sont choisis aléatoirement et, par conséquent, deux exécutions successives ne produisent pas le même résultat.
L’implémentation par Oracle du k-means semble en revanche déterministe, plusieurs exécutions successives produisant le même résultat.
Néanmoins, contrairement à l’implémentation d’Oracle, la fonction kmeans de R accepte que l’on spécifie les points (centroïdes) initiaux. Dans notre cas, puisqu’on connait les chefs de groupes parlementaires, on peut fournir cette information à la fonction:
> centers <- votes2part[which(votes2part$DEPUTE %in% c("Bruno Le Roux","Christian Jacob","Philippe Vigier","Roger-Gérard Schwartzenberg","François de Rugy","André Chassaigne")),3:dim(votes2part)[2]]
> clu <- kmeans(votes2part[,3:dim(votes2part)[2]],centers)
> res <- data.frame(clu$cluster,votes2part$PARTI)
> distrib <- table(res$votes2part.PARTI,res$clu.cluster)
> distrib
1 2 3 4 5 6
Groupe de l'union des démocrates et indépendants 0 0 22 0 0 0
Groupe de la gauche démocrate et républicaine 0 0 0 8 0 0
Groupe écologiste 0 0 0 0 16 0
Groupe Les Républicains 0 184 0 0 0 0
Groupe radical, républicain, démocrate et progressiste 1 0 0 0 0 12
Groupe socialiste, républicain et citoyen 251 0 0 0 0 3
>
> barplot(distrib, main="Distribution des députés par partition",xlab="Partition", col=colpartis, legend=rownames(distrib), args.legend = list(x = "topright", bty = "n", inset=c(-0.3, 0)))
>
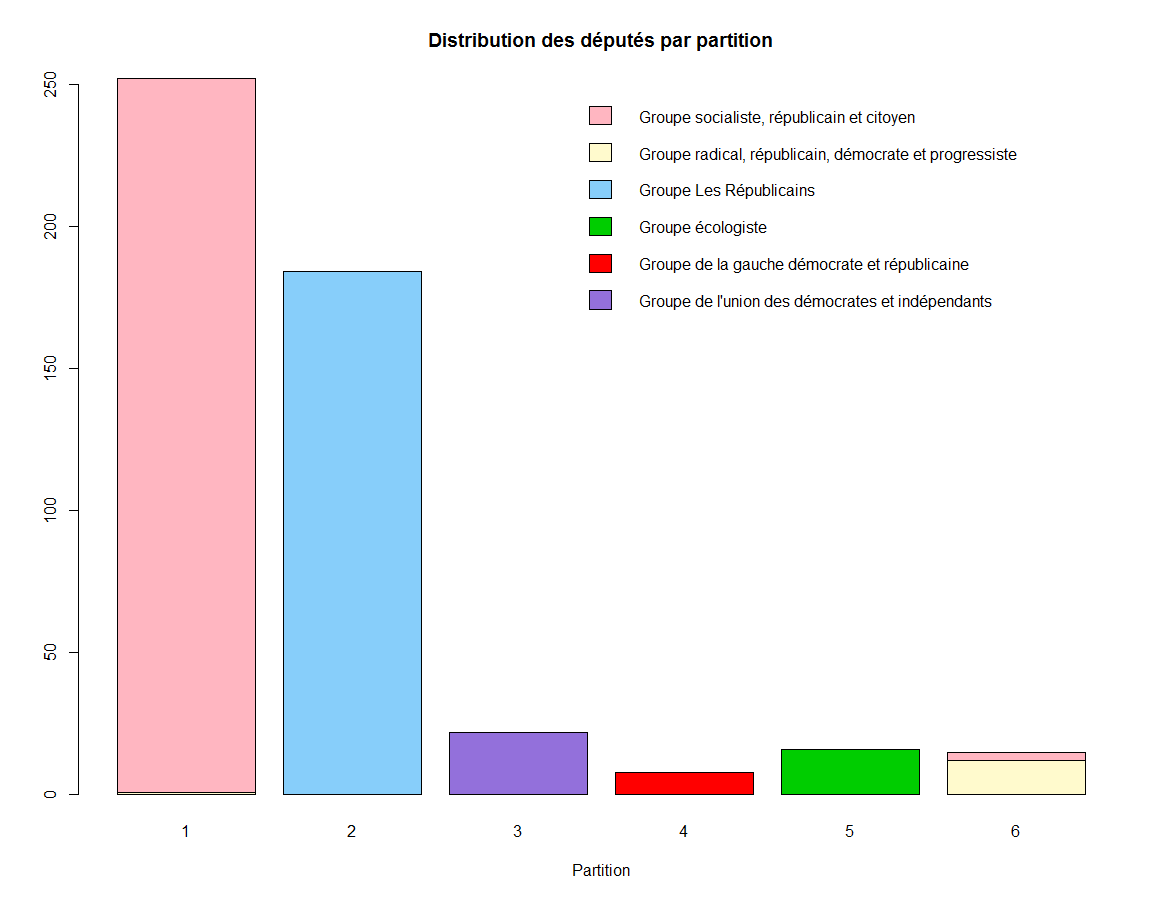
Cette fois le résultat du partitionnement est excellent (et déterministe)!