Régression logistique avec R
Dans la continuité du précédent billet, la régression logistique est mise en œuvre avec R cette fois. Les données utilisées sont identiques.
Chargement et mise en forme des données
A l’aide de ROracle, on peuple les datasets jo_ck_prerio (JO pré-Rio: échantillon d’apprentissage) et jo_ck_rio (JO de Rio: échantillon de test):
> library(ROracle) > ora = Oracle() > cnx = dbConnect(ora, username="rafa", password="rafa", dbname="S1401037:1521/STATPDB") > > jo_ck_prerio <- dbGetQuery(cnx, "select * from JO_CK_PRERIO") > jo_ck_rio <- dbGetQuery(cnx, "select * from JO_CK_RIO") > > dbDisconnect(cnx) [1] TRUE >
Les champs TYPE_EPREUVE, SEXE et PAYS sont ensuite convertis en tant que facteurs. On en profite aussi pour fixer la catégorie de référence (Slalom ici) du facteur TYPE_EPREUVE:
> jo_ck_prerio$TYPE_EPREUVE <- as.factor(jo_ck_prerio$TYPE_EPREUVE)
> jo_ck_rio$TYPE_EPREUVE <- as.factor(jo_ck_rio$TYPE_EPREUVE)
>
> jo_ck_prerio$TYPE_EPREUVE <- relevel(jo_ck_prerio$TYPE_EPREUVE,"Slalom")
> jo_ck_rio$TYPE_EPREUVE <- relevel(jo_ck_rio$TYPE_EPREUVE,"Slalom")
>
> jo_ck_prerio$SEXE <- as.factor(jo_ck_prerio$SEXE)
> jo_ck_rio$SEXE <- as.factor(jo_ck_rio$SEXE)
>
> jo_ck_prerio$PAYS <- as.factor(jo_ck_prerio$PAYS)
> jo_ck_rio$PAYS <- as.factor(jo_ck_rio$PAYS)
>
> summary(jo_ck_prerio)
NOM TYPE_EPREUVE AGE SEXE TAILLE POIDS PAYS
Length:439 Slalom:163 Min. :16.00 F:130 Min. :154.0 Min. : 50.00 Poland : 25
Class :character Sprint:276 1st Qu.:23.00 M:309 1st Qu.:172.0 1st Qu.: 66.00 Germany : 23
Mode :character Median :26.00 Median :178.0 Median : 75.00 Australia: 20
Mean :25.78 Mean :177.6 Mean : 75.19 France : 19
3rd Qu.:28.00 3rd Qu.:184.5 3rd Qu.: 84.00 Slovakia : 18
Max. :42.00 Max. :202.0 Max. :109.00 Spain : 18
(Other) :316
>
Création du modèle
La régression logistique binaire est réalisée à l’aide de la fonction glm pour laquelle on précise l’argument family=binomial :
> log_model <- glm(TYPE_EPREUVE ~ . - NOM,family=binomial,data=jo_ck_prerio)
> summary(log_model)
Call:
glm(formula = TYPE_EPREUVE ~ . - NOM, family = binomial, data = jo_ck_prerio)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.38343 -0.43245 0.00008 0.42094 2.46605
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -2.063e+01 1.075e+04 -0.002 0.99847
AGE -1.785e-03 3.923e-02 -0.045 0.96372
SEXEM -4.230e+00 6.332e-01 -6.680 2.38e-11 ***
TAILLE -1.071e-01 3.840e-02 -2.790 0.00527 **
POIDS 3.649e-01 4.598e-02 7.935 2.11e-15 ***
PAYSAngola 3.770e+01 1.312e+04 0.003 0.99771
PAYSArgentina 1.807e+01 1.075e+04 0.002 0.99866
PAYSAustralia 1.549e+01 1.075e+04 0.001 0.99885
PAYSAustria 1.508e+01 1.075e+04 0.001 0.99888
PAYSAzerbaijan 3.123e+01 1.521e+04 0.002 0.99836
PAYSBelarus 3.333e+01 1.151e+04 0.003 0.99769
PAYSBelgium 1.775e+01 1.075e+04 0.002 0.99868
PAYSBosnia and Herzegovina -2.293e+00 1.521e+04 0.000 0.99988
PAYSBrazil 1.775e+01 1.075e+04 0.002 0.99868
PAYSBulgaria 3.459e+01 1.148e+04 0.003 0.99759
PAYSCanada 1.635e+01 1.075e+04 0.002 0.99879
PAYSChile 1.502e+01 1.075e+04 0.001 0.99889
PAYSChina 1.585e+01 1.075e+04 0.001 0.99882
PAYSCook Islands 1.072e+01 1.075e+04 0.001 0.99920
PAYSCote d'Ivoire 3.460e+01 1.521e+04 0.002 0.99818
PAYSCroatia 1.397e+01 1.075e+04 0.001 0.99896
PAYSCuba 3.522e+01 1.171e+04 0.003 0.99760
PAYSCzech Republic 1.522e+01 1.075e+04 0.001 0.99887
PAYSDenmark 3.350e+01 1.180e+04 0.003 0.99774
PAYSEcuador 3.018e+01 1.521e+04 0.002 0.99842
PAYSEgypt 3.867e+01 1.521e+04 0.003 0.99797
PAYSEstonia 3.445e+01 1.521e+04 0.002 0.99819
PAYSFinland 3.491e+01 1.233e+04 0.003 0.99774
PAYSFrance 1.629e+01 1.075e+04 0.002 0.99879
PAYSGermany 1.472e+01 1.075e+04 0.001 0.99891
PAYSGreat Britain 1.534e+01 1.075e+04 0.001 0.99886
PAYSGreece 1.569e+01 1.075e+04 0.001 0.99884
PAYSGuam 3.637e+01 1.521e+04 0.002 0.99809
PAYSHungary 3.423e+01 1.110e+04 0.003 0.99754
PAYSIndonesia 3.509e+01 1.521e+04 0.002 0.99816
PAYSIran 3.708e+01 1.199e+04 0.003 0.99753
PAYSIreland 1.538e+01 1.075e+04 0.001 0.99886
PAYSIsrael 3.390e+01 1.219e+04 0.003 0.99778
PAYSItaly 1.675e+01 1.075e+04 0.002 0.99876
PAYSJapan 1.685e+01 1.075e+04 0.002 0.99875
PAYSKazakhstan 1.840e+01 1.075e+04 0.002 0.99864
PAYSLatvia 3.435e+01 1.225e+04 0.003 0.99776
PAYSLithuania 3.352e+01 1.130e+04 0.003 0.99763
PAYSMacedonia -1.953e+00 1.282e+04 0.000 0.99988
PAYSMexico 3.276e+01 1.296e+04 0.003 0.99798
PAYSMorocco -3.109e+00 1.304e+04 0.000 0.99981
PAYSMyanmar 3.630e+01 1.521e+04 0.002 0.99810
PAYSNetherlands -4.471e+00 1.166e+04 0.000 0.99969
PAYSNew Zealand 1.684e+01 1.075e+04 0.002 0.99875
PAYSNigeria -4.972e+00 1.521e+04 0.000 0.99974
PAYSNorway 3.477e+01 1.216e+04 0.003 0.99772
PAYSPoland 1.586e+01 1.075e+04 0.001 0.99882
PAYSPortugal 1.663e+01 1.075e+04 0.002 0.99877
PAYSRomania 3.376e+01 1.120e+04 0.003 0.99760
PAYSRussia 1.669e+01 1.075e+04 0.002 0.99876
PAYSSamoa 3.304e+01 1.521e+04 0.002 0.99827
PAYSSao Tome and Principe 3.767e+01 1.521e+04 0.002 0.99802
PAYSSenegal 3.653e+01 1.310e+04 0.003 0.99777
PAYSSerbia 3.314e+01 1.162e+04 0.003 0.99772
PAYSSeychelles 3.297e+01 1.521e+04 0.002 0.99827
PAYSSingapore 3.412e+01 1.521e+04 0.002 0.99821
PAYSSlovakia 1.552e+01 1.075e+04 0.001 0.99885
PAYSSlovenia 1.509e+01 1.075e+04 0.001 0.99888
PAYSSouth Africa 1.869e+01 1.075e+04 0.002 0.99861
PAYSSouth Korea 3.658e+01 1.285e+04 0.003 0.99773
PAYSSpain 1.590e+01 1.075e+04 0.001 0.99882
PAYSSweden 3.487e+01 1.137e+04 0.003 0.99755
PAYSSwitzerland 1.512e+01 1.075e+04 0.001 0.99888
PAYSThailand -1.510e+00 1.521e+04 0.000 0.99992
PAYSTogo -2.431e+00 1.521e+04 0.000 0.99987
PAYSTunisia 3.535e+01 1.183e+04 0.003 0.99762
PAYSUkraine 3.473e+01 1.200e+04 0.003 0.99769
PAYSUnited States 1.492e+01 1.075e+04 0.001 0.99889
PAYSUruguay 3.554e+01 1.521e+04 0.002 0.99814
PAYSUzbekistan 3.422e+01 1.216e+04 0.003 0.99775
PAYSVenezuela 3.137e+01 1.521e+04 0.002 0.99835
PAYSVietnam 3.778e+01 1.521e+04 0.002 0.99802
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 579.17 on 438 degrees of freedom
Residual deviance: 267.27 on 362 degrees of freedom
AIC: 421.27
Number of Fisher Scoring iterations: 18
>
A l’instar de la fonctionnalité de « feature selection » d’ODM, on peut utiliser la fonction step pour réaliser une détermination pas à pas de la meilleure combinaison de prédicteurs:
> step(log_model, dir="backward")
Start: AIC=421.27
TYPE_EPREUVE ~ (NOM + AGE + SEXE + TAILLE + POIDS + PAYS) - NOM
Df Deviance AIC
- PAYS 72 407.80 417.80
- AGE 1 267.28 419.28
<none> 267.27 421.27
- TAILLE 1 275.58 427.58
- SEXE 1 329.21 481.21
- POIDS 1 376.09 528.09
Step: AIC=417.8
TYPE_EPREUVE ~ AGE + SEXE + TAILLE + POIDS
Df Deviance AIC
- AGE 1 407.93 415.93
<none> 407.80 417.80
- TAILLE 1 422.42 430.42
- SEXE 1 474.27 482.27
- POIDS 1 541.79 549.79
Step: AIC=415.93
TYPE_EPREUVE ~ SEXE + TAILLE + POIDS
Df Deviance AIC
<none> 407.93 415.93
- TAILLE 1 422.77 428.77
- SEXE 1 474.39 480.39
- POIDS 1 541.81 547.81
Call: glm(formula = TYPE_EPREUVE ~ SEXE + TAILLE + POIDS, family = binomial,
data = jo_ck_prerio)
Coefficients:
(Intercept) SEXEM TAILLE POIDS
-0.6010 -3.1906 -0.1019 0.2901
Degrees of Freedom: 438 Total (i.e. Null); 435 Residual
Null Deviance: 579.2
Residual Deviance: 407.9 AIC: 415.9
>
La fonction step parvient à la conclusion que seuls les prédicteurs SEXE, TAILLE et POIDS doivent être maintenus dans le modèle final:
> log_model <- glm(TYPE_EPREUVE ~ TAILLE + SEXE + POIDS,family=binomial,data=jo_ck_prerio)
> summary(log_model)
Call:
glm(formula = TYPE_EPREUVE ~ TAILLE + SEXE + POIDS, family = binomial,
data = jo_ck_prerio)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.8981 -0.7873 0.3187 0.7275 2.2077
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -0.60105 3.59533 -0.167 0.867233
TAILLE -0.10189 0.02772 -3.675 0.000238 ***
SEXEM -3.19061 0.44163 -7.225 5.03e-13 ***
POIDS 0.29005 0.03179 9.123 < 2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 579.17 on 438 degrees of freedom
Residual deviance: 407.93 on 435 degrees of freedom
AIC: 415.93
Number of Fisher Scoring iterations: 5
>
Scoring du modèle
La fonction predict permet d’appliquer notre modèle sur le dataframe de test jo_ck_rio:
> rio_pred <- predict(log_model, jo_ck_rio)
> head(rio_pred)
1 2 3 4 5 6
-1.9928707 -1.9928707 -1.5458741 -1.9534234 -0.9501602 -1.0520475
>
Les résultats en sortie correspondent aux valeurs rendues par la fonction logistique utilisant les coefficients obtenus plus haut:
Ici, la variable dépendante est un facteur et l’aide de la fonction glm (?glm) permet de trouver la convention utilisée par R pour définir quel niveau est associé avec le succès 1 ou l’échec 0:
« For binomial and quasibinomial families the response can also be specified as a factor (when the first level denotes failure and all others success) »
Ici, le premier niveau du facteur TYPE_EPREUVE est Slalom:
> levels(jo_ck_prerio$TYPE_EPREUVE)[1] [1] "Slalom" > levels(jo_ck_rio$TYPE_EPREUVE)[1] [1] "Slalom" >
Le point d’inflexion de la fonction logistique étant à 0.5, on considérera que les valeurs supérieures correspondent à une prédiction de la catégorie Sprint.
> rio_pred.bin <- ifelse(rio_pred > 0.5,"Sprint","Slalom") >
On peut alors produire une matrice de confusion afin de mesurer la qualité de nos prédictions:
> table(rio_pred.bin, jo_ck_rio$TYPE_EPREUVE)
rio_pred.bin Slalom Sprint
Slalom 46 15
Sprint 15 108
>
Le taux de réussite des prédictions avec ce modèle logistique binaire est de l’ordre de 84% (46+108)/(46+15+15+108).
Représentation graphique
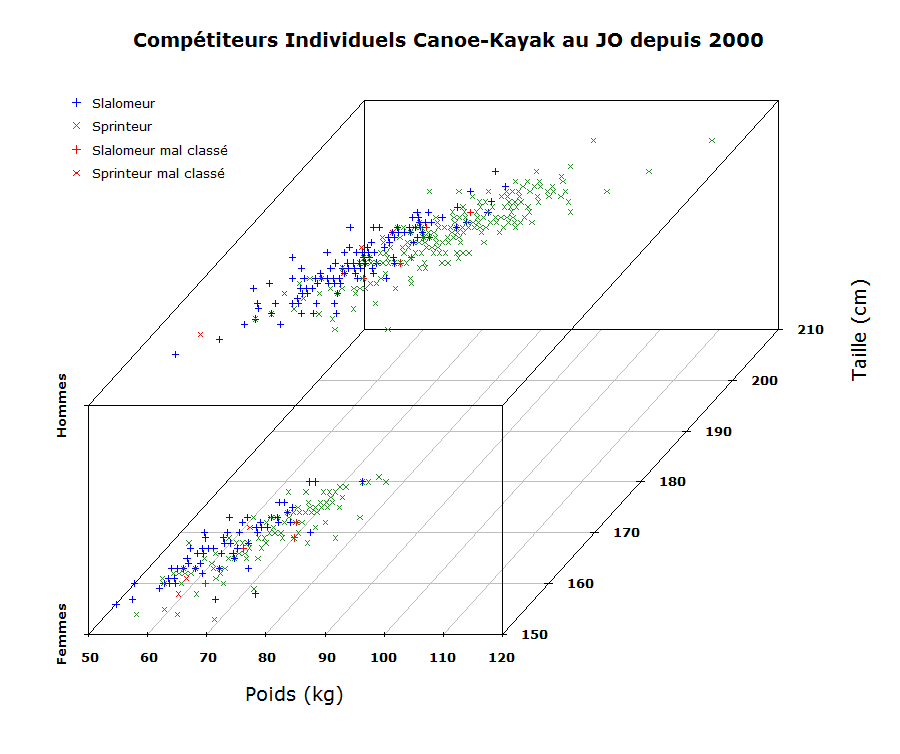
La représentation graphique des données permet de mieux appréhender l’origine des défauts de classification. On remarque bien au passage que les compétiteurs des deux disciplines ont globalement des corpulences différentes:
> prerio <- jo_ck_prerio[,c("TAILLE","POIDS","SEXE","TYPE_EPREUVE")]
> prerio$COLOR <- ifelse(prerio$TYPE_EPREUVE == "Slalom", "blue","forestgreen")
> prerio$PCH <- ifelse(prerio$TYPE_EPREUVE == "Slalom", 3,4)
> prerio <- prerio[,c("TAILLE","POIDS","SEXE","COLOR","PCH")]
>
> rio <- jo_ck_rio[,c("TAILLE","POIDS","SEXE","TYPE_EPREUVE")]
> rio$COLOR <- ifelse(rio$TYPE_EPREUVE == "Slalom", "blue","forestgreen")
> rio$PCH <- ifelse(rio$TYPE_EPREUVE == "Slalom", 3,4)
> rio$pred <- as.factor(rio_pred.bin)
>
> rio$COLOR[which(rio$pred!=rio$TYPE_EPREUVE)] <- "red"
> rio <- rio[,c("TAILLE","POIDS","SEXE","COLOR","PCH")]
>
> jo_ck <- rbind(prerio,rio)
>
> library(scatterplot3d)
> library(extrafont)
Registering fonts with R
> loadfonts(device="win")
Agency FB already registered with windowsFonts().
[...]
Wingdings 3 already registered with windowsFonts().
>
>
> par(family = "Verdana")
>
> scatterplot3d(jo_ck$POIDS, jo_ck$TAILLE, jo_ck$SEXE,
+ main = "Compétiteurs Individuels Canoe-Kayak au JO depuis 2000",
+ xlab = "Poids (kg)",
+ ylab = "Taille (cm)",
+ zlab = "",
+ color = jo_ck$COLOR,
+ angle = 25,
+ pch=jo_ck$PCH,
+ cex.symbols=0.6,
+ z.ticklabs=c("Femmes","Hommes"),
+ lab.z=1,
+ cex.lab=1.2,
+ font.lab=2)
>
>
> legend("topleft",
+ bty="n",
+ cex=0.8,
+ c("Slalomeur", "Sprinteur", "Slalomeur mal classé", "Sprinteur mal classé"),
+ col=c("blue", "forestgreen", "red","red"),
+ pch=c(3,4,3,4))
>