Test t de Student avec R
Dans un précédent billet, un test de Student a été utilisé pour vérifier que le niveau de présence d’un polluant était en moyenne plus élevé dans une zone de l’agglomération de Tours que dans une autre. L’analyse a été menée directement avec les fonctions statistiques SQL d’Oracle 12c.
Dans ce billet, nous allons reproduire les mêmes opérations en utilisant R. Les étapes sont très similaires.
Chargement des données
> air <- read.csv2("C:/RTI/Stats/lig-air-derniere-semaine.csv", dec=".")
> names(air) <- c("Date","Bruyere","Pompidou")
> summary(air)
Date Bruyere Pompidou
19/05/2015 17:00: 1 Min. :-0.20 Min. : 1.80
19/05/2015 18:00: 1 1st Qu.: 6.95 1st Qu.: 9.10
19/05/2015 19:00: 1 Median :10.30 Median :12.60
19/05/2015 20:00: 1 Mean :10.76 Mean :12.77
19/05/2015 21:00: 1 3rd Qu.:14.15 3rd Qu.:16.70
19/05/2015 22:00: 1 Max. :24.30 Max. :28.80
(Other) :160 NA's :1
>
Vérification des conditions d’application du test de Student
- Normalité des échantillons
Les capacités graphiques de R permettent d’utiliser la technique de la droite de Henry pour estimer visuellement si la distribution des échantillons suit approximativement une loi normale:
> par(mfrow=c(2,1)) > qqnorm(air[,2], main="Bruyere");qqline(air[,2]); > qqnorm(air[,3], main="Pompidou");qqline(air[,3]); >
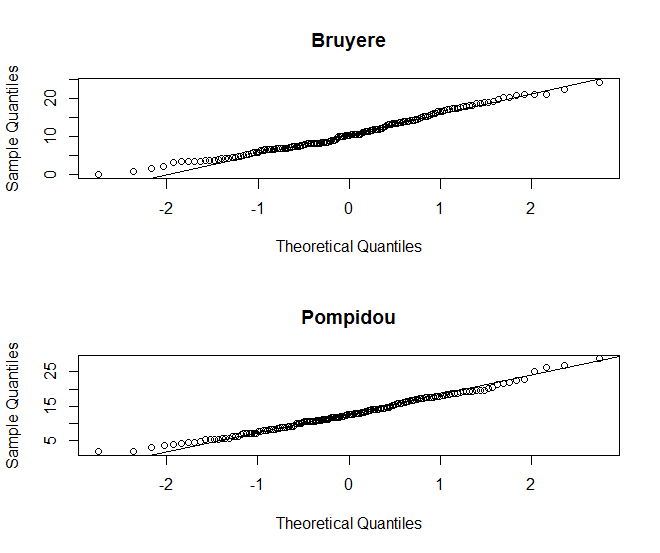
On voit bien ici que sur une échelle Gausso-Arithmétique, les points sont globalement alignés.
Néanmoins, à l’instar de ce que nous avions réalisé en SQL, on peut aussi réaliser les tests de Shapiro-Wilk et Kolmogorov-Smirnov pour valider l’hypothèse de normalité:
> shapiro.test(air[,3]) Shapiro-Wilk normality test data: air[, 3] W = 0.9889, p-value = 0.2197 >
On retrouve les mêmes valeurs W et p que lors du test mené sous Oracle.
L’utilisation du test de Kolmogorov-Smirnov sous R pour valider la normalité nécessite une opération de centrage/réduction des valeurs étudiées (dans la mesure ou pnorm correspond à une loi normale centrée-réduite):
> ks.test((air[,2]-mean(air[,2]))/sd(air[,2]), "pnorm") One-sample Kolmogorov-Smirnov test data: (air[, 2] - mean(air[, 2]))/sd(air[, 2]) D = 0.0834, p-value = 0.198 alternative hypothesis: two-sided Warning message: In ks.test((air[, 2] - mean(air[, 2]))/sd(air[, 2]), "pnorm") : aucun ex-aequo ne devrait être présent pour le test de Kolmogorov-Smirnov >
On retrouve à nouveau les mêmes valeurs D et p que lors du test mené sous Oracle.
- Homoscédasticité
On réalise un test de Fisher:
> var.test(air[,2],air[,3])
F test to compare two variances
data: air[, 2] and air[, 3]
F = 0.9494, num df = 165, denom df = 164, p-value = 0.7393
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.6985702 1.2900302
sample estimates:
ratio of variances
0.949372
>
Les valeurs W et p correspondent au test mené sous Oracle.
Réalisation du test de Student
Finalement, le test t de Student est réalisé (sans l’option var.equal=TRUE, c’est un test de Welch qui est réalisé).
L’argument alternative= »less » permet d’indiquer qu’il s’agit d’un test unilatéral avec un premier vecteur d’espérance inférieure au second.
> t.test(air[,2], air[,3], var.equal=TRUE, alternative="less")
Two Sample t-test
data: air[, 2] and air[, 3]
t = -3.5688, df = 329, p-value = 0.000206
alternative hypothesis: true difference in means is less than 0
95 percent confidence interval:
-Inf -1.079376
sample estimates:
mean of x mean of y
10.75904 12.76606
>
Là encore, on retrouve précisément les mêmes valeurs que lors de l’analyse menée sous Oracle.
Salut !
j’ai également fait le ks.test sous R mais je me suis interrogé
Comment dois-je interpréter le Warning message du ks.test ?
Dois-je conclure qu’il est sans importance ?
Dois-je refaire le test en traitant les ex-æquo? si oui, comment ?
Existe-t-il un test alternatif pour la prise en compte des ex-æquo ?
Merci
Cordialement
Bonjour,
effectivement, l’implémentation du test de Kolmogorov-Smirnov sous R est sensible à la présence d’ex-aequos (?ks.test):
« The presence of ties always generates a warning, since continuous distributions do not generate them. If the ties arose from rounding the tests may be approximately valid, but even modest amounts of rounding can have a significant effect on the calculated statistic. »
Dans le cas présent, mon objectif était de valider que les valeurs obtenues avec R étaient similaires à celles renvoyées par DBMS_STAT_FUNCS.NORMAL_DIST_FIT. C’était bien le cas, j’ai donc ignoré le message d’avertissement. En contexte opérationnel, il vaudrait sans doute mieux recourir à une alternative comme le test de Shapiro-Wilk (utilisé aussi dans le billet).
A+
Raphaël