Arbre de décision avec R
Je réalise ici une analyse similaire à celle du précédent billet en m’appuyant cette fois-ci sur R.
Chargement des données
Les données des vues v_autos_apprentissage et v_autos_test sont respectivement chargées dans les dataframes autos_apprentissage et autos_test:
> library(ROracle) Le chargement a nécessité le package : DBI Warning message: le package ‘DBI’ a été compilé avec la version R 3.2.1 > ora = Oracle() > cnx = dbConnect(ora, username="rafa", password="rafa", dbname="S1401037:1521/STATPDB") > autos_apprentissage <- dbGetQuery(cnx, "select * from v_autos_apprentissage") > autos_test <- dbGetQuery(cnx, "select * from v_autos_test") > dbDisconnect(cnx) [1] TRUE >
Par défaut, les données textuelles (VARCHAR2) sont typées en « character » dans R. Il faut donc passer par une étape de conversion sous forme de facteurs:
> autos_apprentissage$TYP_BOITE=as.factor(autos_apprentissage$TYP_BOITE)
> autos_apprentissage$GAMME=as.factor(autos_apprentissage$GAMME)
> autos_apprentissage$BONUS_MALUS=as.factor(autos_apprentissage$BONUS_MALUS)
> autos_apprentissage$CARROSSERIE=as.factor(autos_apprentissage$CARROSSERIE)
> autos_apprentissage$HYBRIDE=as.factor(autos_apprentissage$HYBRIDE)
> autos_apprentissage$LIB_MRQ=as.factor(autos_apprentissage$LIB_MRQ)
> autos_apprentissage$COD_CBR=as.factor(autos_apprentissage$COD_CBR)
>
> autos_test$TYP_BOITE=as.factor(autos_test$TYP_BOITE)
> autos_test$GAMME=as.factor(autos_test$GAMME)
> autos_test$BONUS_MALUS=as.factor(autos_test$BONUS_MALUS)
> autos_test$CARROSSERIE=as.factor(autos_test$CARROSSERIE)
> autos_test$HYBRIDE=as.factor(autos_test$HYBRIDE)
> autos_test$LIB_MRQ=as.factor(autos_test$LIB_MRQ)
> autos_test$COD_CBR=as.factor(autos_test$COD_CBR)
>
> summary(autos_test)
LIB_MRQ LIB_MOD COD_CBR HYBRIDE PUISS_ADMIN_98 PUISS_MAX TYP_BOITE NB_RAPP CONSO_URB CONSO_EXURB
AUDI :274 Length:654 ES:289 non:654 Min. : 3.000 Min. : 44.0 A:249 Min. :0.000 Min. : 3.800 Min. : 3.000
SEAT :104 Class :character GO:365 1st Qu.: 6.000 1st Qu.: 77.0 M:366 1st Qu.:6.000 1st Qu.: 5.600 1st Qu.: 4.100
SKODA :103 Mode :character Median : 8.000 Median :103.0 V: 39 Median :6.000 Median : 6.400 Median : 4.500
VOLKSWAGEN:173 Mean : 9.546 Mean :120.8 Mean :5.722 Mean : 7.039 Mean : 4.773
3rd Qu.:10.000 3rd Qu.:139.0 3rd Qu.:6.000 3rd Qu.: 7.500 3rd Qu.: 5.200
Max. :48.000 Max. :412.0 Max. :8.000 Max. :22.200 Max. :10.700
CONSO_MIXTE MASSE_ORDMA_MIN MASSE_ORDMA_MAX CARROSSERIE GAMME BONUS_MALUS
Min. : 3.200 Min. : 929 Min. : 929 BERLINE :352 INFERIEURE:110 C (0) :372
1st Qu.: 4.600 1st Qu.:1296 1st Qu.:1296 BREAK :139 LUXE : 85 D (150) : 54
Median : 5.200 Median :1500 Median :1500 COMBISPACE : 45 MOY-INFER :208 G (900) : 51
Mean : 5.598 Mean :1485 Mean :1485 COUPE : 65 MOY-SUPER :203 I (2200): 49
3rd Qu.: 6.000 3rd Qu.:1646 3rd Qu.:1646 MONOSPACE : 26 SUPERIEURE: 48 H (1600): 39
Max. :14.900 Max. :2315 Max. :2315 MONOSPACE COMPACT: 27 N (8000): 29
(Other) : 60
Warning message:
In summary(autos_test) : bytecode version mismatch; using eval
>
Construction de l’arbre de décision
Le package rpart permet de construire l’arbre à partir de l’échantillon d’apprentissage. On exclut les champs LIB_MOD et LIB_MRQ qui n’ont pas d’intérêt informatif.
> library(rpart)
> autos_dt <- rpart(BONUS_MALUS~., data=autos_apprentissage[,!(colnames(autos_apprentissage) %in% c("LIB_MOD","LIB_MRQ"))], method="class")
>
On cherche ensuite à « élaguer » l’arbre de manière à obtenir le meilleur compromis entre le nombre de feuilles et la performance de classification. Ce compromis dépend du critère cp (complexity parameter) dont on peut déterminer la valeur optimale via les commandes plotcp (mode graphique) et printcp:
> plotcp(autos_dt)
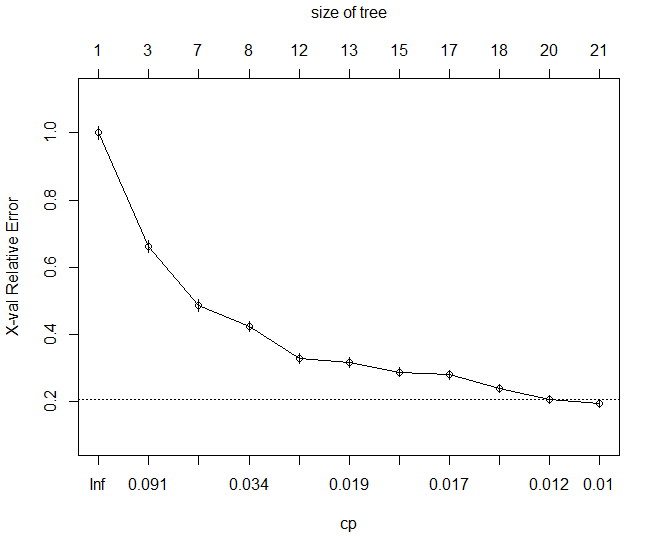
> printcp(autos_dt)
Classification tree:
rpart(formula = BONUS_MALUS ~ ., data = autos_apprentissage[,
!(colnames(autos_apprentissage) %in% c("LIB_MOD", "LIB_MRQ"))],
method = "class")
Variables actually used in tree construction:
[1] COD_CBR CONSO_EXURB CONSO_MIXTE
Root node error: 1329/2722 = 0.48824
n= 2722
CP nsplit rel error xerror xstd
1 0.170429 0 1.00000 1.00000 0.019623
2 0.048345 2 0.65914 0.66215 0.018362
3 0.045147 6 0.46576 0.48608 0.016702
4 0.025771 7 0.42062 0.42363 0.015901
5 0.019564 11 0.31753 0.32807 0.014398
6 0.017682 12 0.29797 0.31603 0.014181
7 0.017306 14 0.26260 0.28819 0.013650
8 0.015801 16 0.22799 0.27991 0.013485
9 0.013544 17 0.21219 0.23928 0.012610
10 0.010534 19 0.18510 0.20542 0.011793
11 0.010000 20 0.17457 0.19413 0.011499
>
Dans l’exemple ci-dessus, l’algorithme s’interrompt pour un CP de 0.01 (qui se trouve être la limite basse par défaut du paramètre). Cela signifie que l’ajout de nouvelles feuilles ne permettrait pas d’améliorer la précision de la classification de plus d’1%.
Dans ce cas précis, l’élagage de l’arbre n’est pas nécessaire puisque la structure finale correspond déjà au CP le plus faible. Néanmoins, le cas échéant l’élagage serait réalisé via la fonction prune:
> optimcp <- autos_dt$cptable[which.min(autos_dt$cptable[,"xerror"]),"CP"] > autos_dt.pruned <- prune(autos_dt, cp = optimcp)
Performance du modèle
La sortie de printcp permet aussi de quantifier la performance du modèle via deux taux d’erreur:
- le taux d’erreur de re-substitution (rel error * root node error): 0.48824 * 0.17457 * 100 = 8.5%.
C’est une valeur biaisée par nature (puisque basée sur la performance de classification de l’échantillon d’apprentissage) et donc plutôt « optimiste ».
On la retrouve en comparant les valeurs réelles de bonus/malus et les prédictions associées pour autos_apprentissage:
> 100*length(which(autos_apprentissage$BONUS_MALUS != predict(autos_dt,type="class")))/dim(autos_apprentissage)[1] [1] 8.523145 >
- le taux d’erreur de validation croisée (xerror * root node error): 0.48824 * 0.19413 * 100 = 9.5%.
Ce taux correspond à la moyenne des erreurs obtenues en appliquant à 10 reprises le modèle sur des sous-échantillons (chaque sous-échantillon étant obtenu par ré-échantillonnage de l’ensemble d’apprentissage dans une proportion 90%/10%).
Ce taux est plus représentatif que le taux d’erreur de re-substitution.
On peut aussi mesurer la performance du classifieur sur notre échantillon de test. Ici, on avoisine 89.3% de classifications correctes:
> 100*length(which(autos_test$BONUS_MALUS != predict(autos_dt, newdata=autos_test[,!(colnames(autos_test) %in% c("LIB_MOD","LIB_MRQ"))],type="class")))/dim(autos_test)[1]
[1] 10.70336
>
Enfin, la construction d’une matrice de confusion permet d’avoir une idée de l’efficacité du classifieur en fonction des différentes classes de bonus/malus:
> conf.matrix <- table(autos_test$BONUS_MALUS, predict(autos_dt, newdata=autos_test[,!(colnames(autos_test) %in% c("LIB_MOD","LIB_MRQ"))],type="class"))
> print(conf.matrix)
C (0) D (150) F (500) G (900) H (1600) I (2200) J (3000) K (3600) L (4000) M (6500) N (8000)
C (0) 364 6 1 0 0 1 0 0 0 0 0
D (150) 5 49 0 0 0 0 0 0 0 0 0
F (500) 0 0 21 1 0 1 0 0 0 0 0
G (900) 0 0 1 34 0 16 0 0 0 0 0
H (1600) 0 0 0 0 21 18 0 0 0 0 0
I (2200) 0 0 0 0 6 43 0 0 0 0 0
J (3000) 0 0 0 0 0 4 5 1 1 0 0
K (3600) 0 0 0 0 0 0 0 4 0 0 0
L (4000) 0 0 0 0 0 0 0 0 10 3 0
M (6500) 0 0 0 0 0 2 0 0 0 4 3
N (8000) 0 0 0 0 0 0 0 0 0 0 29
>
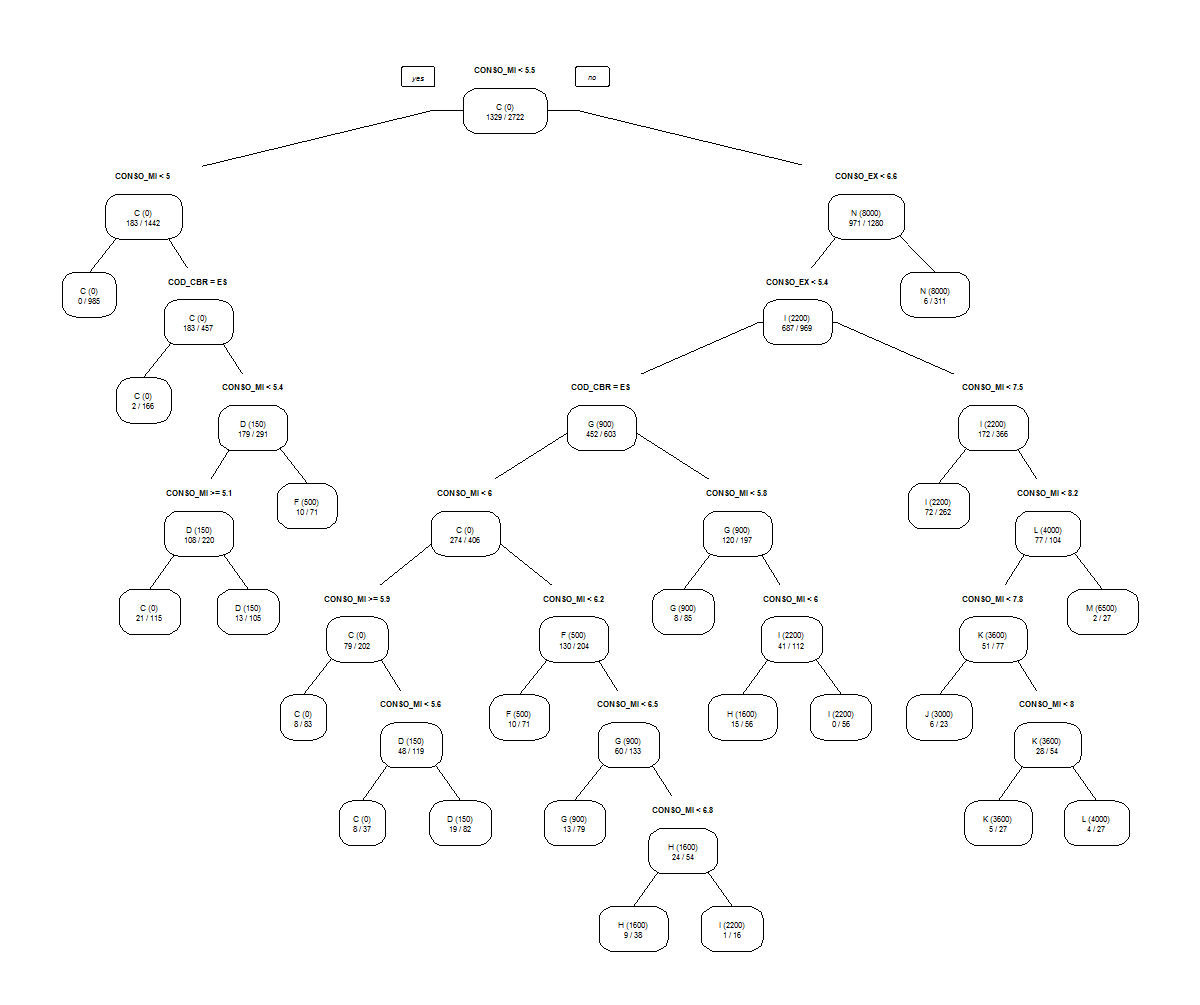
Visualisation de l’arbre de décision
Il peut être intéressant de représenter graphiquement l’arbre de décision avec les règles qui le constitue:
> library(rpart.plot) > prp(autos_dt.pruned, type=1, extra=3)